
最近看了些流计算方面的资料,尤其今天看到的Streaming 101& 102 系列,颇有醍醐灌顶的感觉. 感觉之前听到的很多言论都属于夸夸其谈而不知其然,更莫论其所以然.
背景
当MapReduce横空出世的时候,凭借其强大的分布式批处理能力赢得了业界的广泛认可.
但慢慢的,我们有了新的需求.
- 现在越来越多的业务需要非常实时的数据,比如说twitter/微信朋友圈,微博点赞等等,实时天气预测或者航班监测. Stream可以提供我们需要的短延时.
- 巨大的,快速增长的没有边界的数据集在当代发展环境中是非常普遍的,许多系统都是适应于这种无限扩充的数据集.
- 在数据到达的时候就进行处理,相当于把计算压力分布在不同的时间,帮助实现更加一致性和可预测的资源损耗
What is Streaming?
对于streaming有一个非常具体而简洁的解释: 一种为无限数据集设计的数据处理引擎.
“ prefer to isolate the term streaming to a very specific meaning: a type of data processing engine that is designed with infinite data sets in mind. Nothing more. “
What streaming can and can’t do.
对于流计算的误区:
很长一段时间里,流计算系统都只被局限在提供 低延时,不够准确/推测性 的结果,通常要依赖结合更加强档的批处理系统来提供最终版本的正确结果.
有一个例子是Twitter的 Nathan Marz (creator of Storm) 提出的 Lambda Architecture.
Lambda Architecture 的基本思想是同时运行一个streaming system和一个batch system, 来进行本质上相同的计算.
Streaming system 负责提供低延时,不够准确的结果(无论是因为使用了近似算法,或者因为streaming system本身没有保证足够的正确性). 经过一段时间之后,batch system 运行并且提供数据的最终正式版本. 这在当时是非常绝妙而且成功的一个解决方案,它很好的平衡了batch system所能够保证的准确性和streaming system 所带来的轻巧的低延时.
然而 Lambda system 的维护非常棘手, 你需要去构建,提供并且维护两个独立版本的数据通道(pipeline), 之后在最终对两种结果进行merge.
所以 Tyler Akidau 指出一个设计良好的streaming system 实际上提供了批处理功能的超集.
“Quite honestly, I’d take things a step further. I would argue that well-designed streaming systems actually provide a strict superset of batch functionality. “ -Tyler Akidau
并且他提出流计算想要在这场游戏中赢得batch,只需要做到两点:
Correctness- this getes you pairty with batch.
在本质来说,correctness boils down to consistent storage.即一致性的存储. (这点在事务与分布式事务中详细探讨)Spark Streaming 很多年前第一次出现在大数据领域的时候,当时给黑暗的streaming 世界带来了一致性的一缕阳光.
Tools for reasoning about time — This gets you beyond batch.
two domains of time:
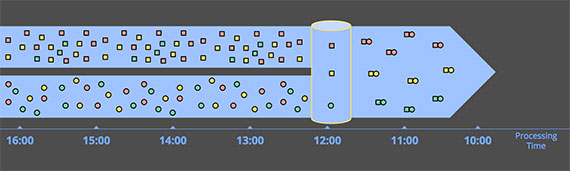
- Event time, 时间发生时刻 occurr
- Processing time, 时间在系统中被观察到的时刻 observe
最理想的情况是,时间发生时间和时间被观察处理的时间是相同的,即时间刚刚发生就被处理. 当然现实是残酷的, 二者的差距不仅不是0, 而且通常是许多因素的一个高可变函数,这些因素包括 输入的数据特征, 运行的引擎,以及硬件.
- 共享资源的局限性,比如说网络拥堵
- 软件原因,比如分布式系统的逻辑
- 数据本身的特征,包括key分布,吞吐量的变化, 或者无序性的变化.
(比如一个飞机上面的乘客,他们在飞机降落时刻关闭飞行模式).
二者关系可见下图:
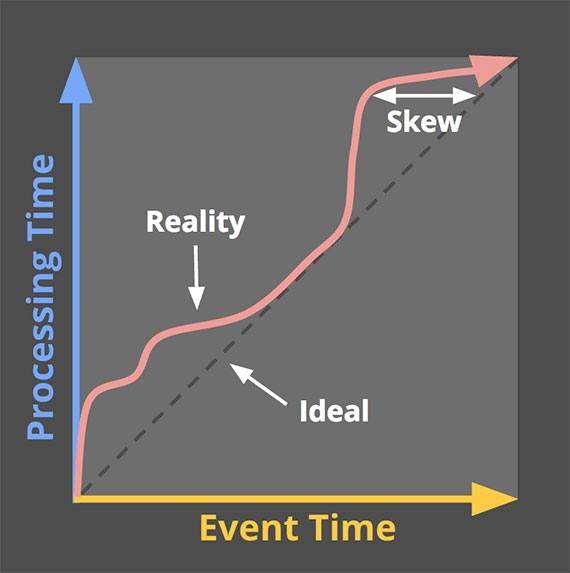
所以由于event occur time 和event process time关系的不可控性和易变性,会带来很多困难,比如说你根据event process time来把数据分块,那就并不能保证同一个even occur time区间发生的事件在处理时刻会落入一个时间窗口. 所以与其去追求一种特别完美的batch切分,不如去容忍这种不确定性, 只是我们要去量化这种”compieteness” 并且尽可能使它达到最优.
Data processing patterns 常见的数据处理模式
最激动人心的时刻来到了.
Bounded data.
简单,直接.
Unbounded data -batch
由于批量计算引擎先于流计算引擎诞生,所以最初的无限数据集是可以用batch engines来计算的. 道理很简单,我们把unbounded data 切分成一个有限数据集的集合,就可以用批量计算来处理.
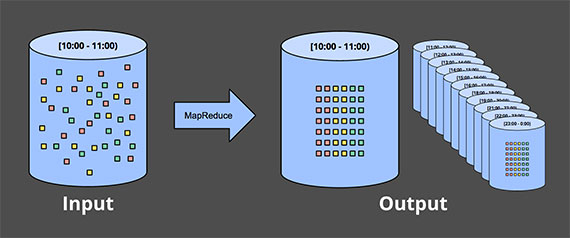
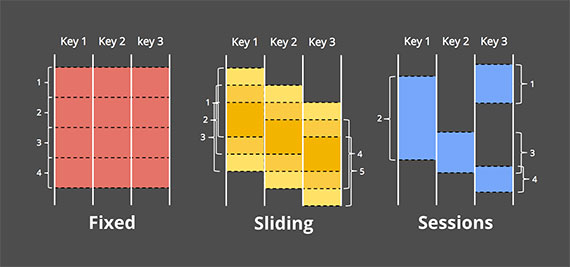
Fixed windows
把数据源切分成等大的切片窗,之后将每个window作为分别独立的数据源进行处理. 比如对于日志的处理.
但可以想象的是,很多系统是有完整性的问题的(completeness), 比如同一个window里面的数据没有同时准备好? 他们产生于不同的无序时刻? 这就意味着你要做一些补偿,比如 将处理延迟到你确定所有需要的数据都收集齐全,或者在晚到的数据到达时再次处理这个window对应的batch.
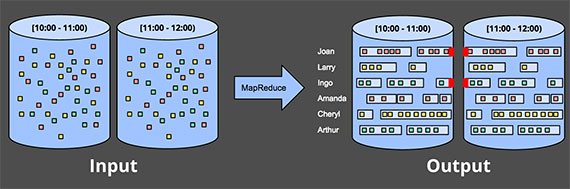
Sessions
batch如果用来处理更加复杂的windowing策略,比如session,就会暴露更多的缺点. Sessions通常被定义为一段用户活跃的时间段,而由于缺少活动而中断(比如你掉线了). 所以sessions会有很大风险被切分到不同的batch. 你可以通过增大batch的覆盖范围来减少这种split,但同时也会增大延迟.
所以用批处理来处理unbounded data 是不理想的
Unbounded data - streaming
在现实世界中, 我们除了需要处理无限多的数据外,通常还有以下特点:
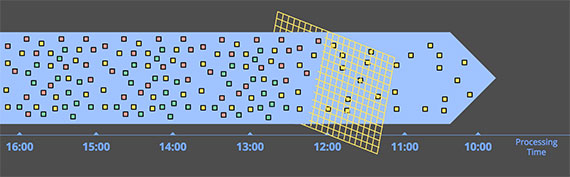
- Highly unordered with respect to event times,即event times 非常无序. 因此需要在处理管道中有某种基于时间的shuffle.
- Of varying event time skew,意思是说你无法保证在 Y时间之后一定会看到X时刻产生的数据.
处理有这些特征的方法有四类:
- Time-agnostic
- Approximation
- Windowing by processing time
- Windowing by event time
Time-agnostic 与事件时间无关
Filtering, 要对全部数据做某种过滤处理,所以who cares 这个数据是什么时候被产生或者观察到的.
Inner-joins 两个数据源中任何一个element到达时刻进行join, 即这种处理逻辑中是没有时间因素的. 但是outer join是不一样的,当一个数据源中的某个element到达的时候,你并不知另一个会不会到达,所以你必须去设定某个timeout,这样就引入了时间因素,也就是某种类型的windowing.
Approximation algorithms 近似算法
- 比如 approximate Top-N, streaming K-means.
- 算法很复杂
- 逻辑有时间因素(事件处理时间)
- 有近似的局限性
- overhead很低, 准确性要求不高时可以满足需求.
Windowing
- 含义是把一个数据集(无论bounded或者unbounded),切分成有限个数的块.
分成3类 见下图
event time windows 的两个缺点:
- Buffering: 由于延长的时间生命期,对数据提出了更多的buffering要求. 不过好在持久化存储是多数数据处理最便宜的需求资源. 因为更多情况下,并不需要整个数据输入在buffer中 比如sum,average, 而是可以通过增量计算的,从而把中间结果存在持久存储中.
- Completeness: 我们无法确定一个window的完整性,因为不知道某个数据什么时候到达.我们只能加入某些近似因素或者做补偿措施来保证严谨的完整性.
To be continued…
References:
[1] MillWheel: Fault-Tolerant Stream Processing at
Internet Scale
[2] Say goodbye to batch
[3] The world beyond batch: Streaming 101
A high-level tour of modern data-processing concepts.
By Tyler Akidau August 5, 2015
