
当你第一次看断背山的时候,印象最深刻的是什么? 有没有可能是他们数羊的片段?? 哈哈,虽然肯定不是,但是今天的问题和数羊有关系. 如果一群羊都在跑, 你怎么数的清? (前提是没有标记)
我先表扬自己一下, 因为在我看来,数羊是对于下面这个问题的一个绝妙的比喻.
可能你已经想到一个方法: 那就是给整个羊群照一张照片,然后自己拿着照片回家慢慢数. 这个方法用术语来表示就是你得到了一个全局快照(global snapshot).通过这个快照,你保留了一个可以恢复可以处理的稳定状态.
然而问题又来了,羊太多,一张照片照不全该怎么办?你怎么保证同时照几张照片呢?
如果你说把羊全部打晕再数, 那我现在就打晕你.
前言
很久不更新了,最近在公司过了一段读论文的日子,为了下一version项目的实时计算部分阅读了很多流计算资料. 包括Apache著名的四大流计算框架. Apache Storm, Spark streaming,Apache Flink,Samza. 以及google刚刚联合apache基金会成功孵化出的大数据处理统一编程模型 Apache Beam( 原型为Google的Dataflow.)
以下挑出一个有意思的点来分享. 这个是Apache Flink 消息传递机制保证和容错机制中确保每个消息被处理且仅被处理一次(所以不会出现消息丢失,同事又不会因为容错中消息重发而导致消息重复)的依赖原理.
背景
无统一时钟

在计算机世界中,各个机器很难有一个统一的时钟来有统一的时间表示. 可能你会想我们人类世界中就可以保证大家对时间的认识一致.比如你和小明约定”我们明早8点的时候同时开始看某个电影”,你说的8点和小明说的8点我们都认为是一个时刻,即你们是可以实现”同时”的.
这个其实是因为我们统一按照格林尼治的时间来做了一个统一. 但是让分布式系统中的每个机器都做到这样是很难的,或者说有一个总的master强制统一这个”同时”的开销是很大的.
如果没有这个”同时”,我们就无法获得一个全局的状态(global state).
全局状态 & 稳定特征感应
而分布式系统中的很多问题都可以化为想要得到全局状态的问题.
比如,你想知道系统是否达到了稳定特征(stable property),譬如死锁问题,你需要这种稳定的状态来探测到系统已经发生死锁.
稳定性的定义是这种状态会永久的持续下去,你可以想象在无阻力环境中的匀速运动或者静止状态.
稳定性感应可以用来做全局快照. 当稳定之后,比如羊群都停止移动或者同速同向平移,你可以在不同时刻照很多照片来合成一张”同时”的全局大照片.
同步快照 & 分布式异步快照
你想要在同一时刻保存系统状态,这个即是同步快照.
分布式异步快照的主要思想是你通过协调,使得他们并不是在同一时刻保存快照,但是快照能够反应出系统数据的处理状态. 即一种”逻辑同步”, 这个是基于Chandy-Lamport算法,严谨地被证明在论文中.(reference中可查)
流式计算中的exactly-once 语意容错机制
消息传输保障机制分为三种:
1.at most once
一条消息经过系统,由这条消息产生的后续tuple在各个处理节点最多会被处理一次,含义就是,出现故障时,不保证这条消息原本应该涉及的所有处理节点计算都顺利完成。
2.at least once
一条消息经过系统,由这条消息产生的后续tuple在各个处理节点至少会被处理一次,含义就是,出现故障时,系统能够识别并进行tuple重发,但是没办法判断是否之前该元组被成功处理完成了,因此可能会有重复处理的情况,对于某些改变外部状态的场景,会造成脏数据。
3.exactly once
一条消息经过系统,不管是否发生故障,由其产生的后续tuple,在所有处理节点上有且仅会被处理一次,这是最理想的情况,即使出现故障,也能符合正确的业务预期,但一般会带来比较大的性能开销。
因为做到exactly-once 有相对较大的性能开销,并且不是幂等的计算所必须,所以并非所有的流计算框架做到了这一点.
相对于micro-batch底层实现的spark streaming,Apache Flink 便使用了分布式快照和检查点(checkpointing)机制来实现了exactly-once 的容错级别.
Flink 进行周期性的全局快照(periodic global state)保存,从而在出现系统failure的时候,只要从上一次保存成功的全局快照中恢复每个节点的恢复状态,然后再使源数据节点从相应快照标记源数据节点重新开始处理即可恢复无措运行状态(Kafka可以做到这一点).
Asynchronous Barrier Snapshot(ABS)
同步快照有以下两种潜在的问题:
- 需要所有节点停止工作,即暂停了整个计算,这个必然影响数据处理效率和时效性.
- 需要保存所有节点/操作中的状态以及所有在传输中的数据(比如storm中的tuples),这个会消费大量的存储空间.
轻量级的异步栅栏快照可以用来为数据流引擎提供容错机制,同时减小的存储空间需求.
因为ABS只需要保存一个无环拓扑中每个操作节点的处理状态(operator states).
Apache Flink 就使用了ABS的机制.
当运行可以分为几个阶段的时候,快照是可以不包含每个task节点间的通道状态的.
Stages divide the injected data streams and all associated into a series of possible executions where all prior inputs and generated outputs have been fully processed.
The set of operator states at the end of a stage reflects the whole execution history, therefore, it can be solely used for a snapshot. The core idea behind our
algorithm is to create identical snapshots with staged
snapshotting while keeping a continuous data ingestion.
这段话太经典.
可以通过切分源数据来划分阶段,每个集合的源数据也代表了其所需要的计算. 当上一个集合的输入数据以及输出都被完全处理,就代表上一个阶段结束了.
所以当一个阶段结束时,操作节点的状态可以代表这整个个运行历史,从而快照可以仅仅依赖于operator states.
这些阶段可以通过周期性的在源头出插入一些栅栏(barrier)来划分. 这些栅栏起到了阶段的标记作用,然后跟着数据流通过整个数据处理pipeline,知道系统的sinks.
全局状态在这个过程中,被增量地构建, 即当每个处理tast接收到对应id的栅栏的时候对自己的状态进行快照,而每个节点异步的快照共同组成了一个阶段(stage)
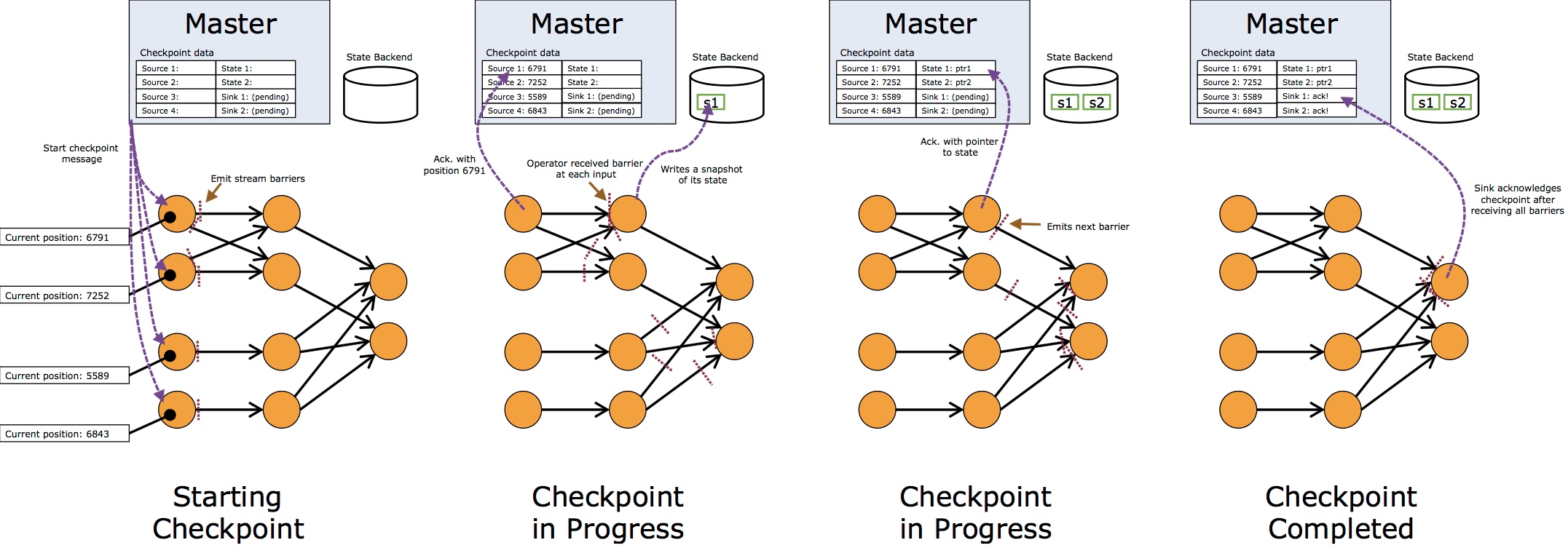
详细的过程可以见下图, Source1,2,3,4 在接到Master的checkpointing消息时,
保存自己的消息消费状态,然后释放一个barrier(包含一个id标记).
当之后的task节点在接收到barrier时,停止处理下一条数据,马上对自己的状态进行快照并且持久化存储, 并且记录这次状态的id, 快照保存之后继续输出barrier并恢复数据梳理流程.
当数据sinks收到所有barriers并且进行自身状态保存之后,也进行ack的checkpointing.
论文算法如下:
看到这里,你会数羊了吗?
参考资料:
Lightweight Asynchronous Snapshots for Distributed Dataflows
by Paris Carbone, Gyula Fora ,Stephan Ewen, Seif Haridi1, Kostas Tzoumas
http://vinoyang.com/2016/05/22/flink-data-streaming-fault-tolerancer/
Distributed Snapshots: Determining Global
States of Distributed Systems by
K. MANI CHANDY University of Texas at Austin
and LESLIE LAMPORT Stanford Research Institute
