继 批处理之外的世界 和 如果让你去数羊-论分布式异步快照原理
第三篇流计算相关的文章与Apache最新的Apache Beam相关.
分久必合
Apache Beam 是Google 闭源项目开源趋势和整个开源大环境交错而诞生的.
上个月10号, Apache软件基金会宣布,Apache Beam项目孵化成功,也成为Apache的顶级项目.当年Google以著名的三篇论文 Google File System,MapReduce,BigTable 开启了大数据处理的伟大时代,但是在工程实现上内部闭源. 精力旺盛的开发者们当然不会闲着, 在三篇论文的基础上诞生出整个开源 Hadoop 生态系统. 包括一系列流计算的框架,如上篇提到过得Apache Spark,Apache Storm,Apache Flink等.
之后Google也走上了开源之路,其中一个大动作就是将Google Cloud Dataflow 贡献给Apache基金会,供整个开源社区添砖加瓦,即现在的Apache Beam.
如下是这个优美的时间线:
2014.12 Google releases the Cloud Dataflow Java SDK
2010 Flume Java(Beam’s API)
2013 MillWheel( Watermarks,exactly-once,Windows)
2016.2 Cloud Dataflow java SDK becomes Apache Beam
Apache Beam是什么东东?
A unified programming model designed to provide efficient and portable data processing pipelines.
关键词有三点:
- unified: 用统一的编程模型,来适用于batch和streaming的情景.
- efficient: 在分布式环境下提供了workload balance和straggler问题的解决方案.
- portable: 用Beam 编程模型写出的数据处理pipeline可以在不同的引擎上运行,包括Apache Apex,Apache Flink,Apache Spark,和Google Cloud Dataflow.
其实还包括一个特征:
- extensible:你可以写新的SDKs(写不同语言的接口给user用) ,IO connectors(当你有一个数据存储的良好实现时) ,transformation libraries.
所以有了Apache Beam你需要的就不再是去甄选一系列数据计算框架, 其中你要付出很多学习代价而是用这个统一的编程模型设计出你需要的数据处理pipeline, 然后通过pipeline runner的翻译 ( pipeline runner是由不同的流计算引擎通过Beam给出的runner APi提供 ) 生成适合于你所选择的分布式数据处理后端的API, 从而可以运行在这些引擎上.
论文中一个更加完整的定义:
Allows for the calculation of event-time ordered results,windowed by features of the data themselves,over an unbounded,unordered data source,with correctness, latency, and cost tunable across a broad spectrum of combinations.
Separates the logical notion of data processing from the underlying physical implementation,allowing the choice of batch,micro-batch, or streaming engine to become one of simply correctness,latency and cost.
Apache Beam提供的抽象:
- pipeline: 封装整个数据处理任务,从始至终. 所有Beam driver程序都需要创建一个pipeline.形状是一个 DAG (directed acyclic graph),点是数据,边是变换.
- PCollection: pipeline的每一步的输入和输出.
- Transform: 代表一个数据处理操作.
- IO Source and Sink: 读取或者写入外部数据源的封装.
当我们谈论Beam的时候,我们在谈论什么?
可以从四个维度来理解,也是google用来阐述beam的方法:
1. What
are you computing?
即我们的business logic是什么,我们的pipeline是用来完成什么事情.
打个比方,比如一个在线游戏,每个玩家产生分数,我们需要实时统计每个玩家的分数总和.
类比于MapReduce 的map-shuffle-reduce 三阶段,Beam首先提供了两个原语- ParDo, groupByKey. ParDo类似于map,作用于单个element,groupByKey类似于Shuffle,将muti-map 装换成uni-map,针对于相同的key做一个集合,然后送去下游作reduce.
2. Where in event time?
如果是去处理一个batch的数据,很简单, 用Beam无非是换了一套API来定义需要的数据处理. 类似去读一个文件,一个数据库.
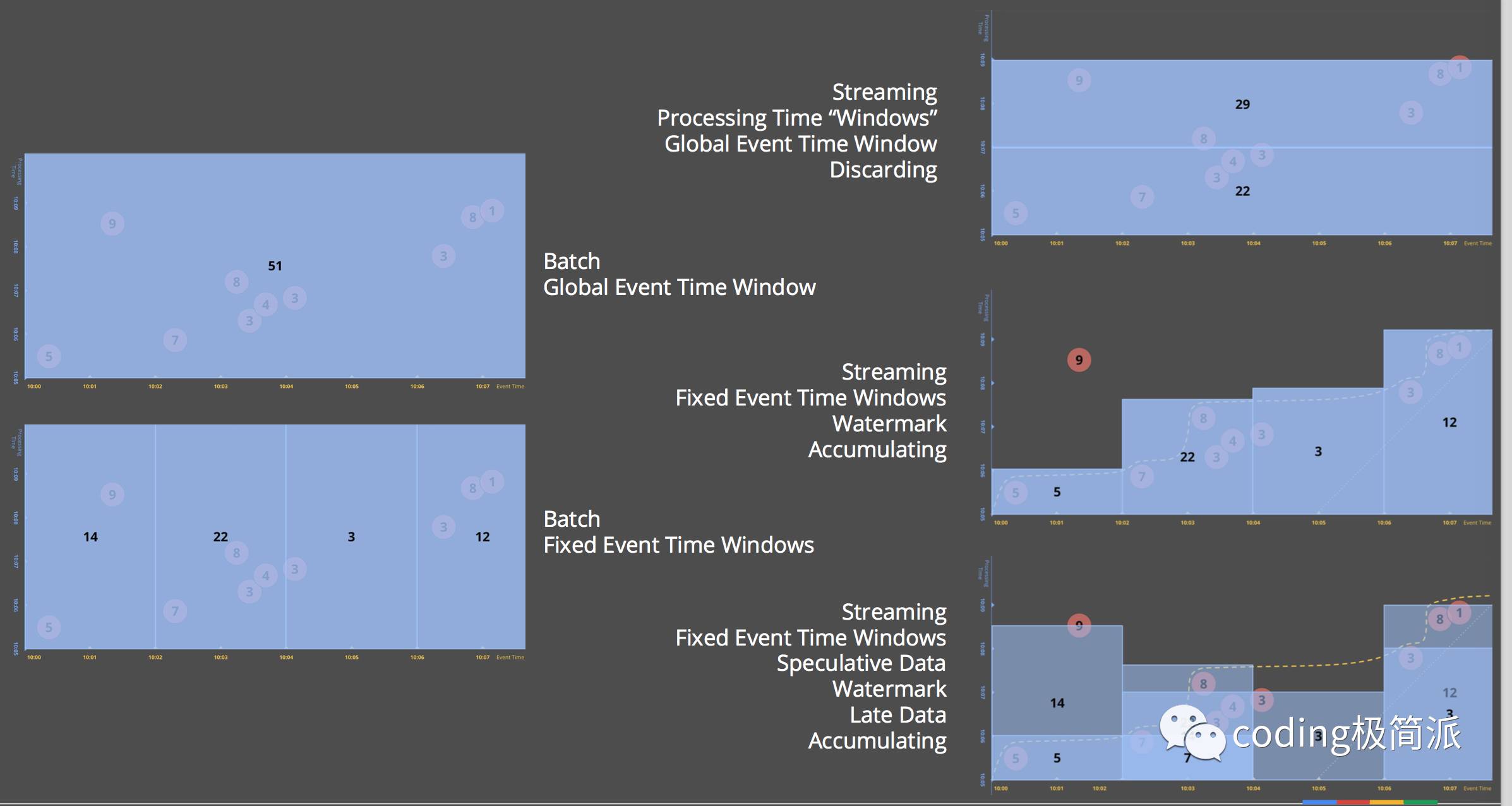
但是当我们处理stream (流数据) 的时候就需要考虑时间的问题. 因为数据源源不断而且无序,我们作groupByKey的时候根本无法知道数据流什么时候完结,或者说根本不会完结. 所以必须根据逻辑时间做一个windowing.即根据时间把数据集切分成有限长度的chunks. Windowing方法可以看之前文章.
3. When in processing time?
对时间需要作如下两个区分:
- Event time: 事件发生时间
- Processing time: 事件处理时间
再祭出这张经典的图.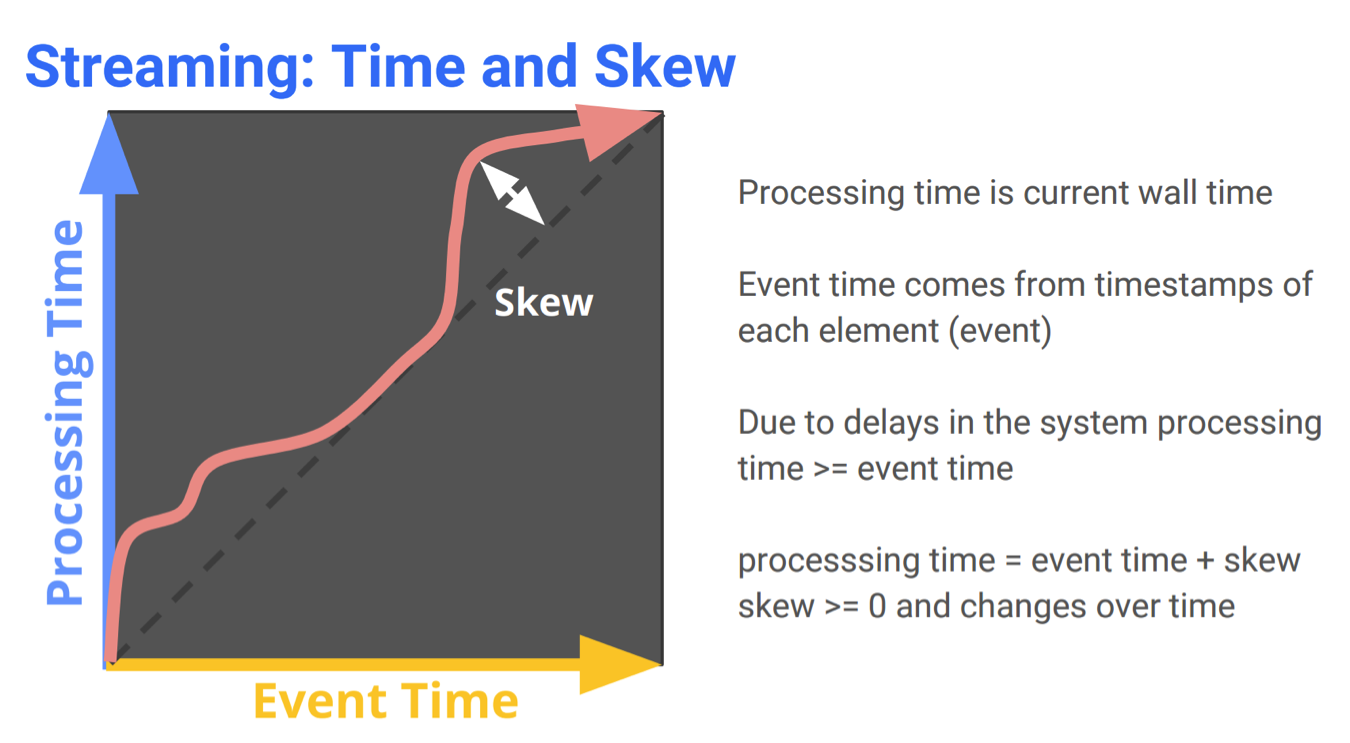
在理想情况下,event time和processing time是重合的,中间没有skew. 但在真实世界中,由于通讯延时,pipeline的序列化,scheduling algorithms或者一些耗时的操作,都会造成skew是对于time的无序变化的函数
Watermark 是用来将skew可视化的一种比较好的方法,是一种global progress metrics.
watermark是一种根据事件发生时间判定输入完整性的标识.一个标识值 time X 的水印的含义是” 时间X内发生/产生的数据都被观察到了”. 即它是一个lower bound.
A watermark is a notion of input completeness with respect to event times.A watermark with a value of time X makes the statement: “all input data with event times less than X have been observed.” As such, watermarks act as a metric of progress when observing an unbounded data source with no known end.
|
|
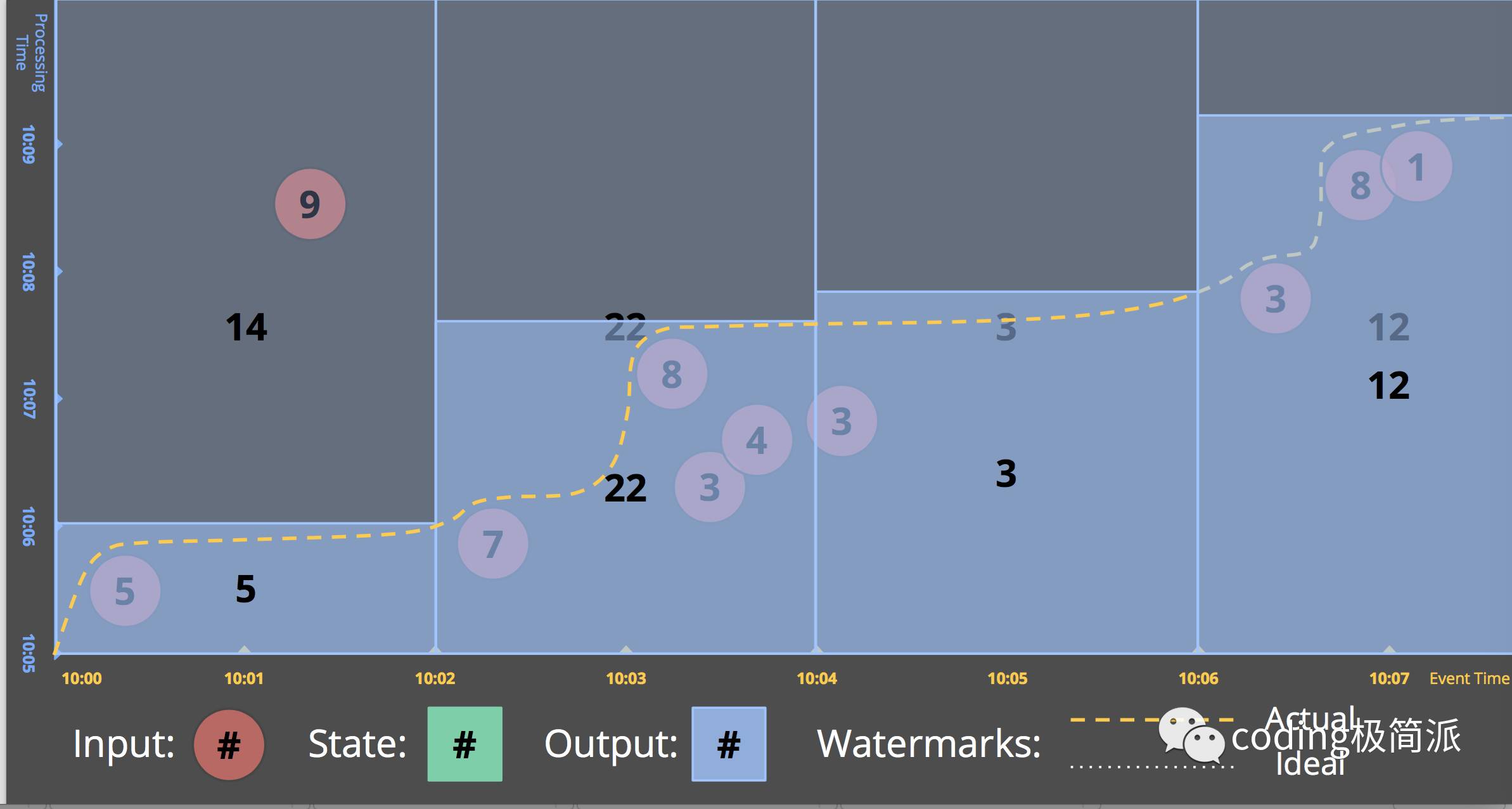
即我们要当watermark线穿过window的时候进行结果输出. watermark很显然是个heuristic 的值,很难准确的预估watermark.
|
|
意味着系统当它认为它全部处理完了这个窗口的数据就输出结果.
上面通过windowing加上watermark的辅助模型还是存在一些问题.
首先, 上面的情况还是需要等到数据完结,而数据流可能根本没有完结.
其次, watermark由于是heuristic的,必然存在准确性的问题.
可能too fast,那么就会出现在watermark之后出现的late data.可能too slow,因为watermark是全局进程metric, 如果一个data非常慢,那么整个pipeline可能被拖延.所以只用watermark作为窗口结果触发信号可能会带来全局结果的延迟.
而且那么显然我们需要增加其它的触发装置.
Triggers are the concept to control when data is emitted.
Dataflow Model.这是一段很经典的:
A useful insights in addressing the completeness problem is that the Lambda Architecture effectively sidesteps the issue: it does not solve the completeness problem by somehow providing correct answers faster;it simply provide the best low-latency estimate of a result that the streaming pipeline can provide, with the promise of eventual consistency and correctness once the batch pipeline runs.If we want to do the same thing from within a single pipeline, then we will need to provide multiple answers (or panes) for any given window.
Triggering 给我们带来更大的自主性而且和Windowing是互补的.
- Windowing 决定where in event time对data进行分组以待后续处理
- Triggering 决定when in processing time groupings的结果输出作为panes.
eg.
|
|
4. How do refinements relate?
对于一个window的很多pane之间的关系,triggers system同时提供了不同refinement模式:
- Discarding
- Accumulating
- Accumulating & Retracting
|
|
可以通过如下一张图来看一系列概念和API加入之后对数据处理过程的影响: